Extracting Data Lineage from BigQuery Logs: A Guide


Extracting data lineage from a data warehouse like BigQuery can be complicated because unlike traditional relational databases we rarely have foreign keys or database constraints to fall back upon. Complicating the picture even further, common data workflows like ELT (Extract, Load, Transform) incentivize users to duplicate data making it difficult to trace precisely which data is being used where and by whom.
In some cases it's possible to trace lineage by leveraging information from a transformation tool like dbt, but what if this isn't feasible? That's where BigQuery log parsing comes in handy - a powerful method to extract data lineage directly from the warehouse itself.
BigQuery Logs: Your Entire Data History

Most BigQuery operations generate reference logs related to the action, like creating or updating a table. These logs are generated by default as part of your initial configuration meaning they ought to exist dating back to your first interaction with the tool. By parsing the relevant logs we should be able to trace the entire history of data within the warehouse.
You can find reference materials for BigQuery logs on the Google Cloud website but the easiest place to start is inside the Logs Explorer in the GCP console. It provides a visual platform to browse logs before diving into writing code.
Let's start by applying the following filter to our Query Logs
protoPayload.serviceName="bigquery.googleapis.com" AND resource.type="bigquery_project" AND protoPayload.methodName="google.cloud.bigquery.v2.JobService.InsertJob"
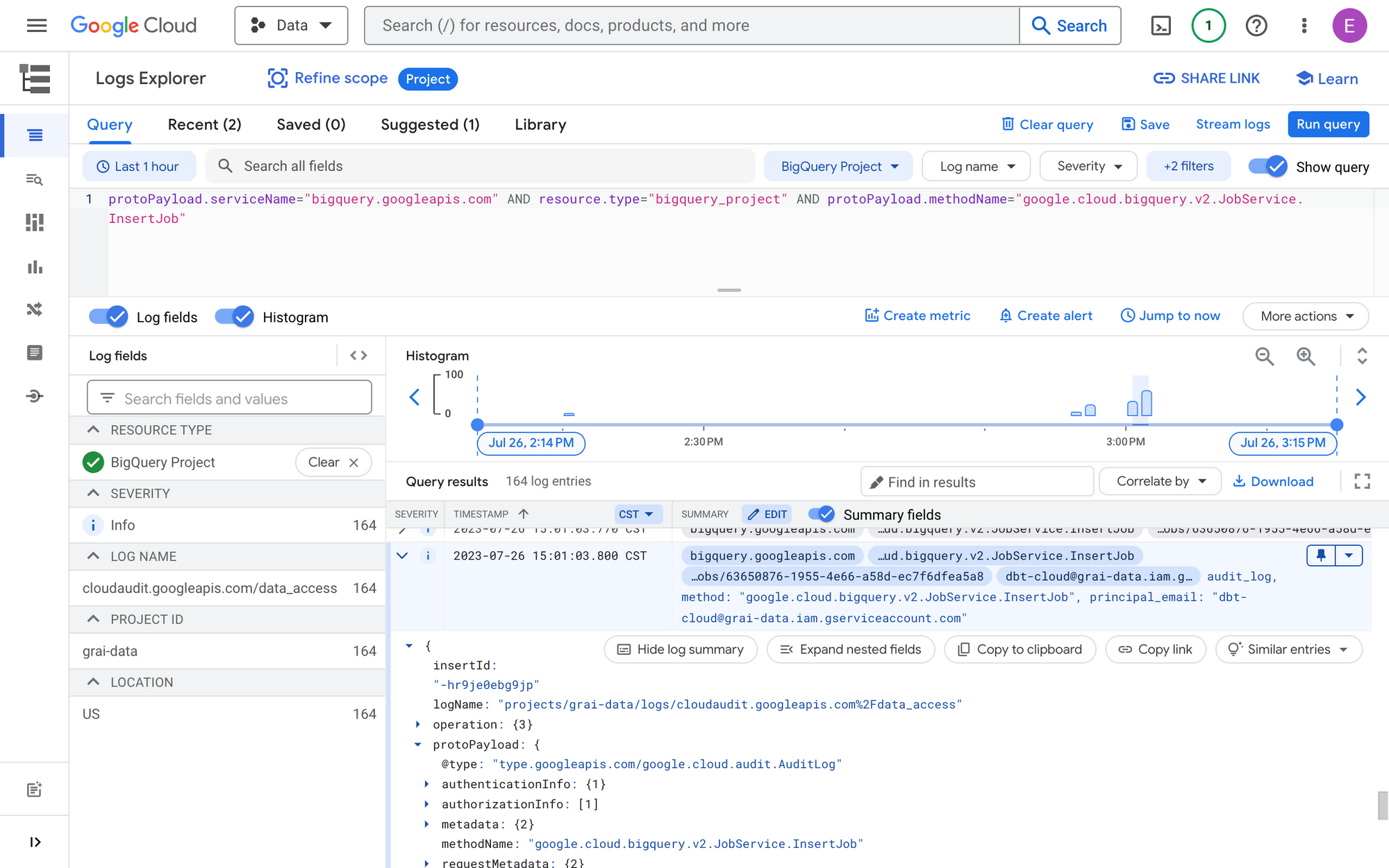
The resulting payload will look something like this
{
insertId: "-k96538e6lstm"
logName: "projects/grai-data/logs/cloudaudit.googleapis.com%2Fdata_access"
operation: {3}
protoPayload: {
@type: "type.googleapis.com/google.cloud.audit.AuditLog"
authenticationInfo: {1}
authorizationInfo: [1]
metadata: {2}
methodName: "google.cloud.bigquery.v2.JobService.InsertJob"
requestMetadata: {2}
resourceName: "projects/grai-data/jobs/26db7d8d-3502-41d5-9648-df5576f4cdaf"
serviceName: "bigquery.googleapis.com"
status: {0}
}
receiveTimestamp: "2023-07-26T20:01:04.539065588Z"
resource: {2}
severity: "INFO"
timestamp: "2023-07-26T20:01:03.662606Z"
}The information needed to build out data lineage is found inside the protoPayload field
protoPayload.metadata.jobChange.job.jobConfig.queryConfig.destinationTableprotoPayload.metadata.jobChange.job.jobStats.queryStats.referencedTables
These two field provide a mapping for each query from destination to reference tables.
Things to Keep in Mind
Although the logs will trace all the way back to when you started using BigQuery, over time the connections between tables will probably have evolved. In order to guarantee your lienage is up to date, you'll need to filter logs over a shorter window; too short and you'll miss infrequently run pipelines, too long and you'll identify outdated or no longer applicable lineage.
It's also worth noting that BigQuery logs encompass all activities, so you might need to filter out certain datasets or tables. Queries run against INFORMATION_SCHEMA, which often aren't relevant, are also included.
To simplify log reading, Google provides libraries like this Python library.
Grai
Grai extracts data lineage from Google BigQuery logs and, as an open source project, you can see our implementation on GitHub here. It is easy to get started with a free cloud account app.grai.io/register.